I took advantage of the long weekend to finish up the first release of the jDeploy desktop app. This has been many months in development, and I’m happy with the result. I think this should eliminate most of the hurdles that stopped new users from adopting it. With the new template gallery, it is possible to create a new Swing or JavaFX project, and publish it to GitHub or npm for others to download in just a few seconds.
Pytube is a great little Python utility for downloading videos from youtube as .mp4 files. It has a command-line interface that makes downloading videos as simple as entering the following command:
$ pytube https://www.youtube.com/watch?v=....
Replace the URL with the Youtube URL of the video you want to download.
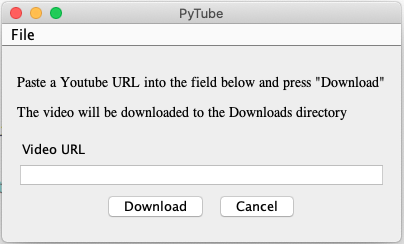
To make things even easier, I wrote a shellmarks wrapper script for this that provides an intuitive GUI form.
Simply paste in the URL and press “Download”, and it will download the video to your “Downloads” directory.
Installation
Pytube installation instructions can be found here.
The TLDR of the install instructions, if you have Python 3 already installed, is to open Terminal and enter:
$ pip install pytube
If pip happens to be the python2 version, you can try
$ pip3 install pytube
instead.
The Shellmarks installation instructions can be found here
The TLDR of the install instructions, if you have npm installed, is to open Terminal and enter:
$ sudo npm install -g shellmarks
I have uploaded the shellmarks wrapper script here
To install it in shellmarks begin by opening shellmarks by opening Terminal and running
$ shellmarks
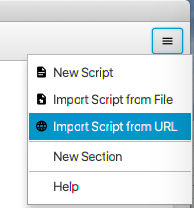
After shellmarks opens, open the menu in the upper right corner and select “Import Script from URL”
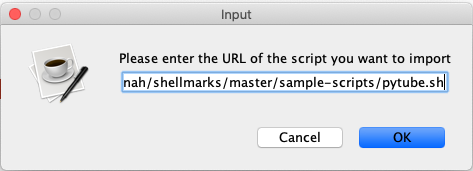
You will the be prompted to enter the URL to the script:
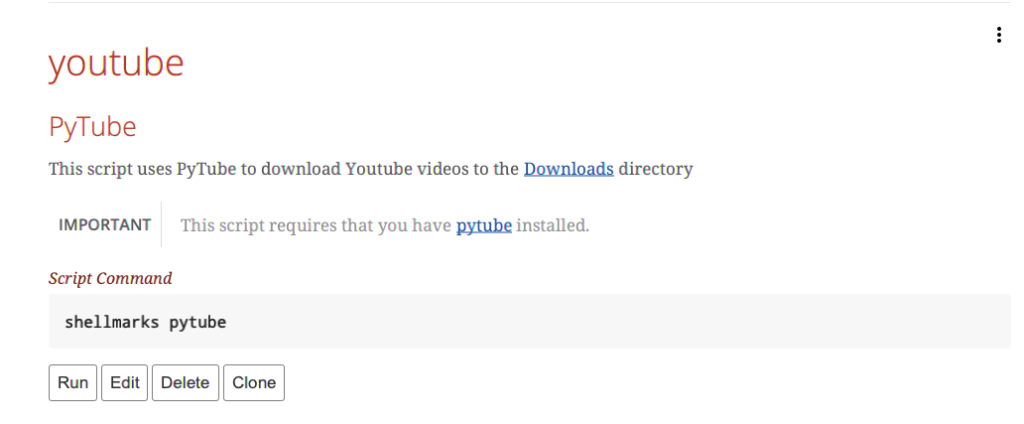
This will install the script and refresh the shellmarks catalog. You should now see an entry as follows:
Press “Run” to run the script. You’ll see the dialog prompting you for the video URL you want to download.
Paste any youtube URL in here and press “Download”. You’ll be able to see the progress of the download in the terminal you used to open shellmarks. When the download is complete, it will open the video in your preferred movie player.
NOTE: This script was developed for MacOS, and would need to be modified slightly to work on Linux or Windows.
You can now access this script directly from within Shellmarks anytime. If you want to run it directly from the command-line you could also simply run:
I used to be the “Web Coordinator” in a university faculty, and I often had to provide tech support to the office staff. One morning I received an urgent call from one of the program assistants (let’s call her Carol) who had misplaced her notes, which, among other things, told her how to use her computer. I jogged down to her office, and found her with a panicked look on her face.
“What am I going to do, Steve?” she asked. “I’ve lost everything. I need to print out the reports for [something or another] and I don’t remember how to do it”.
Carol was a product of a time before computers, and had adapted to her new overlords with difficulty. She was only a few months away from retirement, but without her notes, it would be a rocky send-off.
“Don’t worry. I’m sure we can figure it out”, I assured her. “Do you remember which program you use to print the reports?”
“No.”, she replied. “I wrote it down in my book. But I can’t find my book”.
You’ll be relieved to know that she eventually found her book, and was able to print her reports. Earlier that morning she had been thumbing through some files in one of those big metal file cabinets, and had forgotten that she placed her book on top of the files. Luckily it was still there the next time she needed a file.
At the time, I recall finding a lot of humour in Carol’s predicament. It was further confirmation that my parents’ generation, of which Carol was a member, were clueless about technology. Imagine needing a book to tell you how to do your job?!
Fast forward twenty years. I now keep an exercise book where I write down notes on …. how to do my job. At the beginning of each day, I write the date at the top of the page, and I write down a short to-do list. I refer back to my previous entries and copy outstanding items into my list for today. In the back of the book I write down things that I will need longer term, like passwords.
If I lost my book, I’d be in a tight spot.
We will all be Carol some day.
My Own Crisis of Complexity
If only I could keep all of my development projects in my book.
I have more development projects on computer than I can easily enumerate. If I had to guess, it would be more than 300, less than 1000. At any given time, I have somewhere between 5 and 10 projects that I’m actively working on, and an another 30 or 40 that I’m regularly maintaining. Projects span many different computer languages, build tools, IDEs, and server types. Each project is associated with its own set of standard and obscure tasks. Despite almost all of these tasks being automated by build scripts and CI, the complexity of maintenance can still be overwhelming. When returning to a project that I haven’t worked on in a while (months/years/decades), it still takes a while to grok the project and figure out how to build it, test it, and deploy it again.
Projects that use Maven or Gradle are generally easier to dust off than, for example ANT, or ad-hoc projects. A working mvn package or gradle build command can help with building up some early momentum, but it is still only the beginning. Sometimes I get the “Build Successful” message, and then think to my self “Oh good, it builds! … um ..Now what?”
“I know I had a development server set up somewhere to run this before. Let’s see if I made a script to start that up.”
“Which server is this deployed to. And what passwords do I need?”
“The certificates are expired… how do I generate those again?”
“Oh.. there are build profiles called ‘production’, ‘release’, ‘live’, ‘beta’, and ‘staging’. Which one is the one.”.
“Ugh…. I hope I left some clues in the README”.
“Damnit! I can’t remember where I saved that project. Was it in ‘Projects’, ‘Xcode Projects’, ‘NetBeans Projects’, ‘tests’, ‘demos’, ‘work’?!!! Maybe I didn’t save it on this computer? Is it on Github? If so, does github have all the latest changes?!”
A Place for Everything and Everything In Its Place
To summarize, my problem is two-fold:
I don’t remember where I saved many of my projects.
I don’t remember how to use (i.e. build/test/deploy) my projects once found
What I really need is a book-like medium that includes a searchable catalog of all of my projects, along with any instructions required to use the project. Bonus if this catalog can include buttons or menus to perform the project’s automated tasks.
Over the weekend, I decided that it was time to solve this problem once and for all, so I built Shellmarks.
Shellmarks provides a live catalog of all of my shell scripts including documentation and GUI launchers, all in one place.
Tuxpin: A Case Study
This morning I added an entry for Tuxpin so that I can easily start and stop the development server, as well as deploy it to production. The Tuxpin server app is a PHP/MySQL application. It is built using Xataface, which provides command-line scripts to start and stop the development Apache and MySQL servers. For deployment, I use a bash script that uses rsync to upload the app to the production server.
Up until now, when I want to work on Tuxpin, I start by opening Terminal, navigating to the tuxpin directory, and running xataface start – which starts up Apache on localhost port 9090 with the app.
When I want to deploy it I run bash deploy.sh.
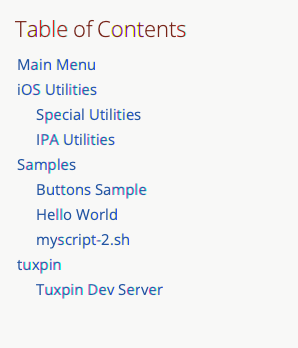
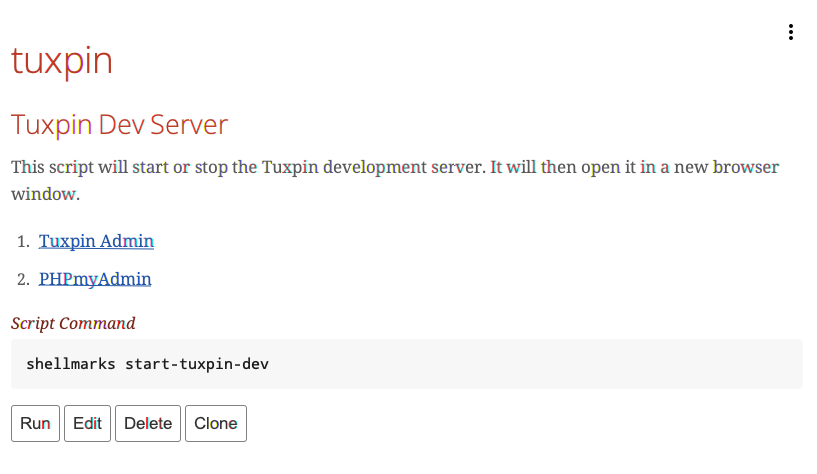
Frankly, this isn’t too bad. However, I can imagine a slightly older version of me returning to this project after many months, or even years, and not remembering what to do. For the benefit of this future self, I have just created a Tuxpin management script in Shellmarks. When he wants to work on Tuxpin, all he needs to remember to do is open Shellmarks. He can then do a simple “Find” for “Tuxpin”, or he can find it in the table of contents:
The Tuxpin section, in shellmarks includes some very short documentation, links to the development server and PHPMyAdmin pages (that will open in the default web browser if the development server is running), and a button to manage the development server:
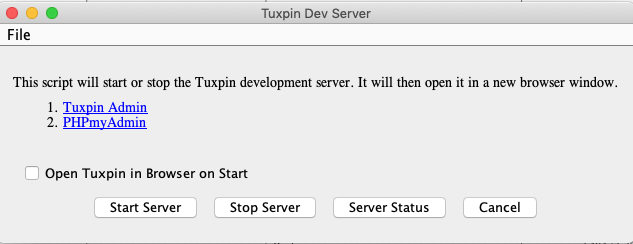
Pressing the “Run” button brings up a server management dialog with buttons to Start and Stop the server, and another button to show the server status:
This makes it dead simple to start working with the project. My future self won’t need to remember anything. He can figure it all out from the GUI.
The Script
The script is pretty simple.
Let me describe what’s going on here. The script has two parts:
The first part is a regular bash script that does the starting/stopping/status checking according to the values/presence of certain environment variables.
The second part (after the exit 0 line) is the dialog definition that shellmarks uses to build the dialog.
The documentation shown in shellmarks is set in the __description__ property. Its content is parsed as Asciidoc, so it can include links, headings, etc…
The buttons are defined by sections, whose names correspond with environment variables used by the script.
For example, the following definition results in a “Start Server” button being displayed in the dialog:
I still remember my first computer programming book. It was a glossy, black, brick of a book on PERL 5. I had started building web pages a few months prior, using the copy of Adobe PageMill that came with my bondi-blue iMac. It didn’t take long before I outgrew the “what you see is sort of what you get†interface of PageMill and started coding the HTML by hand. And it wasn’t long after that, that I entered the world of “copy-and-pasting Javascript†to gain a level of interactivity in my pages – or at least some scrolling status bar text. I started with a free Tripod account, but soon upgraded to “paid” so I could be rid of that pesky banner ad in the header.
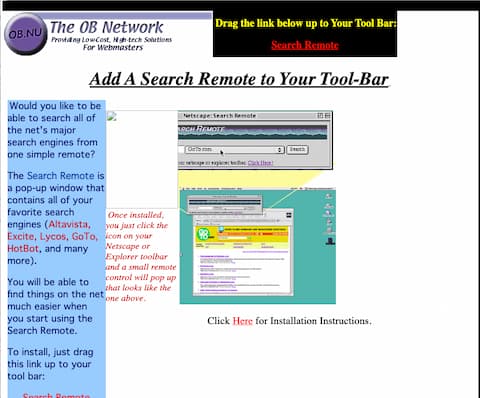
In those early days, I learned mostly by viewing the page source of other webpages, and tried to make sense of the HTML code. One of my first projects was a “Search Remote” – basically a popup search window where people could select from a list of popular (and unpopular) search engines, and enter a query. We provided links that Netscape and Internet Explorer users could drag up to their bookmarks bar to make it easy to open the remote. At the time, there were a few search engines, notably GoTo.com, that would pay you a penny or two for each search query, so I would place these engines first in the list, and wait to get rich. I didn’t get rich, but I did learn a lot about HTML, Javascript, and search engines, and I pushed up against their limitations pretty quickly.
Below is a screenshot of the search remote installation page that I pulled from a Wayback machine capture from 2001. It’s missing some images, but you can get the idea.
Screenshot pulled from the Wayback machine showing the install page for the Search Remote. Capture was from 1999. It’s missing a few of the images.
Back then, all of the search engines were pretty bad, so it was common practice to do a sort of “pub crawl†through all the main ones until you found what you were looking for. You’d start with Altavista (the search engine with the largest index), then you’d try Excite and Yahoo. If you still didn’t find what you were looking for you might try Lycos, Infoseek, or even AskJeeves. This is where my Search Remote comes in. Rather than have to navigate to 6 different search engines’ websites, you could perform all the searches from one place. It worked pretty well, but It still required the user to perform separate queries for each search engine. I wondered if there was a way to let the user perform a single query and have all of the results from the different engines combined into a single result set.
Meta-Search Engines
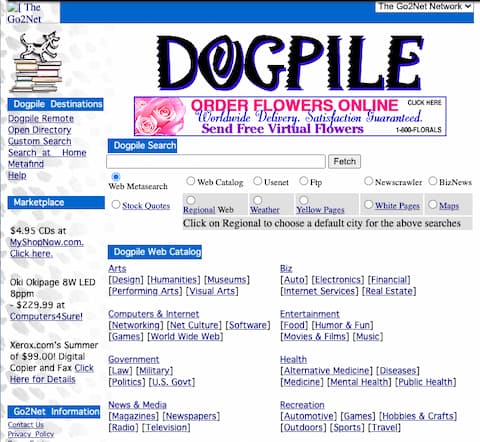
Sometimes, when you’re stuck on a problem, the watershed moment is simply learning the correct terminology for what you want to accomplish. In my case, as I soon learned, the name for what I wanted to build was a “meta search engineâ€, and I was not the first person to conceive of such a thing. Meta-search engines would allow a user to submit a single search query to a server-side CGI script, which would relay the query to 5 or 6 major search engines, in the background, and return all of the results back to the user. Some of them would merge the results into a single set, and sort them according to its own relevancy algorithm. Others would keep the results separate, presenting them on a webpage organized by search engine. Dogpile, my favourite meta-search engine at the time, would use the first method: merge the results into a single list, so it felt like a first-class search. (Side note: Just did a search and it looks like Dogpile still exists).
Dogpile meta search as it appears in the wayback machine from Sept. 2, 1999)
Without a server-side script, it is really hard to write a meta-search engine. This was before AJAX, so the only way to load things from the server from Javascript was using submission forms, and frames. We didn’t even have iframes yet. I tried to build one using pure Javascript, but the results left something to be desired. The best I could do was create a window with a separate frame for each search engine. This worked okay when there were only two search engines, but anything more than that and your “productivity†gains get lost in the clutter of tiny frames.
CGI: The Undiscovered Country
I think that most programmers have a certain resistance to learning new technologies, I was no different. I had cultivated familiarity with Javascript and HTML, but server-side programming was a remote country whose border crossings might as well have been guarded by barbed wire and machine guns. Not until I had exhausted all avenues on the Javascript side of that border, did I decide to venture forth into the untamed world of PERL. I started with things that were freely available online, such as the CGI specification, and the odd PERL tutorial. But the online ecosystem for programming tutorials was sparse, and discoverability was poor – nothing like today, where you can type in just about any programming topic you want, and find tutorials, examples, videos, tutorials, open source projects, and memes enough to keep you busy for months.
One day in my travels, I came across a PERL meta-search script that someone had posted on Hotscripts (or some similar free cgi script site). I printed it out with my Epson 740 inkjet printer, and proceeded to study it. At the time, it was a completely foreign language to me. I recall curling up in bed, on the couch, and in the hot-tub for hours at a time with these pages, poring over it line by line, trying to understand what was going on. It was like one of those pictures they used to display in shopping malls, where, at first, it looks like just a mess of textures, but if you stare at it long enough, you start to see a 3-D image emerge. This script, which, at first, was just a sequence of gibberish, would start to reveal its structure to me in fleeting moments of clarity.
The hours I spent studying that script were important to my growth as a programmer. I still didn’t fully understand what everything meant, and I certainly couldn’t have written my own search script yet, but it did provide me with a feel for what PERL looked like and, strangely, what it felt like. I was ready to graduate to the next level: an actual computer programming book.
Did I mention that I was broke at the time. I had started making webpages just at the end of a six month failed entrepreneurial adventure with a friend, and I was down to about twenty dollars in my bank account on a good day. Luckily, I was living at Casa de my parents where rent was reasonable (free), but I didn’t have a lot of money to spend on frivolities. Or essentials. That was OK, because I was going to be getting rich from my search remote any day now.
To the Bookstore
So, when I entered my local Chapters to shop for computer books, I might as well have been shopping for high priced commercial real estate, as both were out of my price range. Computer books went for anywhere from $60 to $120 depending on how “hot†or specialized the topic was. Lack of funds did not deter this dreamer, though. I scanned through the tables of contents of several dozen books, trying to identify the one that spoke most directly to my interests. When I was a child I used to spend hours examining the toys section of the Sears Christmas catalog, imagining what it would be like to have all of these cool toys and sets. This was that, except replace “Masters of the Universe†with “Mastering PERLâ€.
After what seemed like minutes, but was probably closer to an hour, I had settled on this PERL book. It promised me close to a thousand pages of secrets that, up until now, the universe had greedily kept from me. All I had to do was figure out how to pay for it. A rich benefactor, perhaps?
That rich benefactor ended up being my Dad. I made a deal with him to build a website for his band if he bought the book for me. It was a win win. This book was my first real glimpse into the world of programming. Every page opened my eyes to new possibilities. Things I could build. With every new concept, my mind would start wandering to computer programs I had used in the past, and wondering if I could build something like them – or better.
I could fill a school gymnasium with the spaghetti code that this book (and the hundreds that followed it) inspired. When I later got a job, I started buying a new computer book every payday. Sometimes three or four books. Books on Java, PERL, PHP, HTML, Flash, Servlets, Applets, Game development… you name it. I was hooked. When computer books became more affordable and discount stores like “Half-priced Computer Books†started popping up, I was no longer only buying books on topics that interested me. I began buyings books that I might someday be interested in. I thought I’d won the lottery when, one day, I found a bookstore that was going out of business, and the owner said I could fill 4 big boxes with books for only $100.
Side note: See my post about that time I wanted Star Wars on LaserDisc but ended up with more than I had bargained for. Same personality traits seemed to dominate there as did here.
We are now almost twenty years removed from the computer books hay day. Book stores stock a paltry few books on programming now, and buying books on Amazon isn’t the same. I like to be able to pick up a book, thumb through it, and, um, smell it before I buy it. It’s not a purchase – it’s an experience.
I still frequent the computer books section of Value Village to see if I find anything interesting. Some recent hauls included The Macintosh Bible (7th Edition, 1998), Core Web3D (1999), and Core Swing Advanced Programming (2000). I love reading the preface and introduction sections. They add history and context to these old technologies, and serve as a sort of time capsule that reveals how the world looked to software developers at that time. I love reading 20+ year old predictions about the future, and laughing about how wrong they were, or marvelling at how spot-on they were.
A few of the retro computer books that I picked up recently from Value Village
Old man yells at cloud, reflects on good ol’ days
I wonder, if I were just getting started now, would I still gravitate towards the thousand-page textbook as a preferred method of learning? Or would I just watch a Youtube video. Information is so much more accessible than it was in the nineteen hundreds and there are many new forms of media that are available. There are online communities, question/answer sites, online courses, and video tutorials for just about everything imaginable on Youtube. For free! I suspect that “kids†these days don’t even bother with books. If that’s the case, then oh what a shame. They are missing out on a rich, comprehensive, noise-free medium that gives pure escape from the real world.
I’m not sure how many computer books I currently own. Probably more than 200 and less than a thousand. Most of them are stored away in boxes, spread between my parents’ basement, my garage, my furnace room, and my office, but few coveted titles still enjoy the prestige of sitting on my bookshelf.
My latest project
The Search Remote didn’t exactly strike gold, but I have high hopes for my most recent project, Tuxpin, which builds on my love for audiobooks and podcasts. It is an app (available on both iOS and Android) that allows you to listen to webpages in your podcast app. That project was built using many of the same technologies that I learned how to use at the beginning of my programming journey. PHP, MySQL, and Java. Sadly, it doesn’t contain a single line of PERL.
]5 The website for my latest project, Tuxpin, which allows you to listen to webpages in your podcast app.
Footnote:
I might have the original files for the search remote still stashed away on some 4 gigabyte hard drive, but it would require a lot of effort to retrieve it. But, in the same spirit that supplanted reference books with Google+Stack Overflow, I decided to do a quick search on the Wayback machine to see if it had any record of my debut web project. To my delight, they had both my “Homepage†project, and the search remote project. They are missing most of the images, but the page structure is there, and the search engine select lists are intact so you can see which search engines we supported. I’m impressed at the comprehensive list that I amassed. I must have had a lot of time on my hands.
I love reading, but I don’t have time to “just read” so I tend to consume a lot of written material in “audio” format. This allows me to “read” while I do other things, like walking, driving, cleaning, and cutting the lawn. I “read” a lot of audio books, and follow a short list of podcasts. For the past year or so, I’ve also been experimenting with the latest in neural text-to-speech systems like Amazon Polly for converting blog posts into audio format so that I can listen to them during my walks. The results are surprisingly good. In many cases, I actually prefer the “machine” narration to a human narration. The voice is natural-sounding and consistent.
My favourite type of book (or blog post) is one that tells a true story, especially stories that intersect my personal lived experience. E.g. Stories about the birth of technologies that I use or remember. Insider accounts behind the scenes of movies or TV shows that I have watched. Memoirs of people who experienced certain events that remember living through. The more I “read”, the more specific my “tastes” become. You might say I’ve become more demanding of writers.
One of the most important qualities that I look for in writing is the ability to “take me there”. Books that give a mere account of what happened are barely better than reading a wikipedia article. I want a story to transport me into the time and place in which the described events occurred. I want to feel like a fly on the wall, so that I can imagine what it was like to be living in the story. Memoirs and personal anecdotes have a natural advantage for achieving this level of intimacy because the default is to see the events through the story-teller’s eyes. However, it is still possible to miss the target by focusing too much on sequence of events, and not enough on setting the scene and conveying how it felt to be there.
“The map is not the territory” is a well-known mental model that provides an analogy of what I’m looking for in a story. One way to explain this model is to consider that a map of Paris is not Paris. It is only a map the shows you where things are located from a birds-eye view. It doesn’t provide you with any information about what it feels like to walk the streets of Paris, or experience any of the historical landmarks. When I read a story, I want it to provide me with the territory. I can get the map off of Wikipedia or other reference sources.
My first exposure to this sort of story-telling was Console Wars by Blake J. Harris. It tells the story of the early nineties’ battles between Sega and Nintendo using a technique called as “Scene-based storytelling”. I had never experienced anything quite like it. It felt almost like I was living through a movie, as each bit of history was told through a scene. I don’t know how he was able to put together such a vivid picture the characters and conversations, but however he accomplished it, the end result was magic.
I immediately read his follow-up book History of the Future which uses the same technique to similarly vivid results.
These two books raised the bar for me, and I still have not found anything that quite “takes me there” like they do. I’m always looking, so any recommendations are appreciated.
More recently I’ve started “reading” the Mad Ned Memo, that includes stories from the computer/software industry by a 40-year veteran. His posts are always insightful, and usually combine a theme or timeless truth with some entertaining anecdotes. Not only do his stories “take me there”, they also take me back to my own parallel experiences in my early days of software development. I really wish I could find more content like this.
If you have done any type of software development, or participated in the development of long forgotten projects, I’d love to read about your experiences.
This is the third video in my series about our new online tool, Codename One initializr, which allows you to generate a Maven starter project for a native mobile app in one click. The first video showed how to generate the starter project, and run it in the Codename One simulator. The second video showed how to build and deploy the project on an Android device. In this video I show how to build and deploy the project on an iOS device.
TLDW (Too Long Didn’t Watch):
This video starts out with my Codename One project already opened in IntelliJ. See this post for steps on how to generate this project.
In the video I demonstrate two different approaches for building the iOS app.
Locally (0:55-2:45) – Requires a Mac with Xcode Installed.
Using Build Server (6:45-8:35) – Can be built on Windows, Linux, or Mac. With no special requirements beyond Maven and the JDK. You just need a free Codename One account.
NOTE: I also show how to generate your iOS certificates and provisioning profiles using the Certificate Wizard (2:45-6:45), as this is required to build apps for iOS.
Building Locally
The local build option generates an Xcode project, which we then open and build using Xcode.
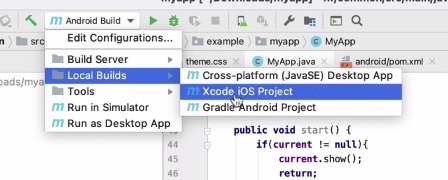
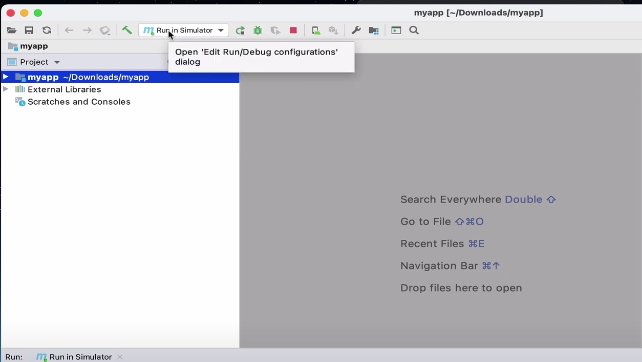
To trigger this build, select “Local Builds” > “Xcode iOS Project”:
Then press the “Run” button.
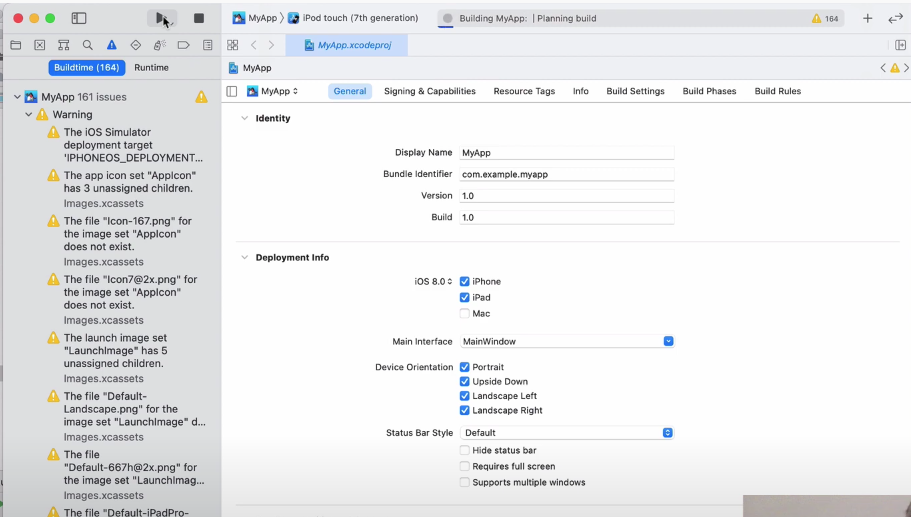
It takes the ParparVM compiler a minute or two to do its thing, but when it’s done, it opens the generated Xcode project in Xcode.
Once opened, I press the “Run” button on the Xcode toolbar and wait while it compiles the project. When it is done, it opens the iOS simulator with my app running in it.
Building with the Build Server
One of the nice things about Codename One is that it provides a build server with all of the native build tools installed and up-to-date. This simplifies the process of building native apps greatly. You can build your project for iOS, Android, Mac Desktop, Windows Desktop, Windows UWP, and Javascript without requiring any special build tools installed beyond the JDK. Building for any of these targets is as simple as pressing a button, or running a Maven goal.
Generating Certificates
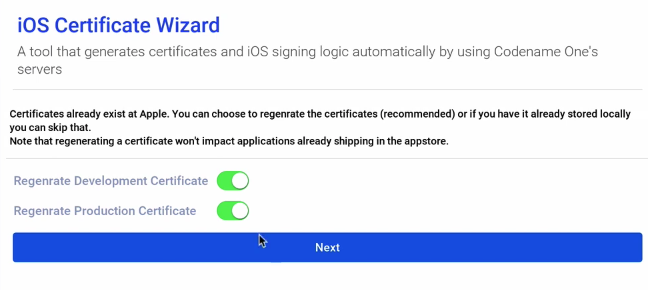
Building for iOS requires that you have an Apple developer account. Additionally, Apple requires you to generate certificates and provisioning profiles for your apps. This is by far the most painful part of app development. To help ease the pain, Codename One provides a certificate wizard to help generate these. Before I can submit my first iOS build, I need to walk through the certificate wizard to generate these certificates. The certificate wizard process starts at approx 2:45 in the video, and runs until 6:45.
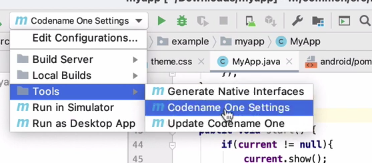
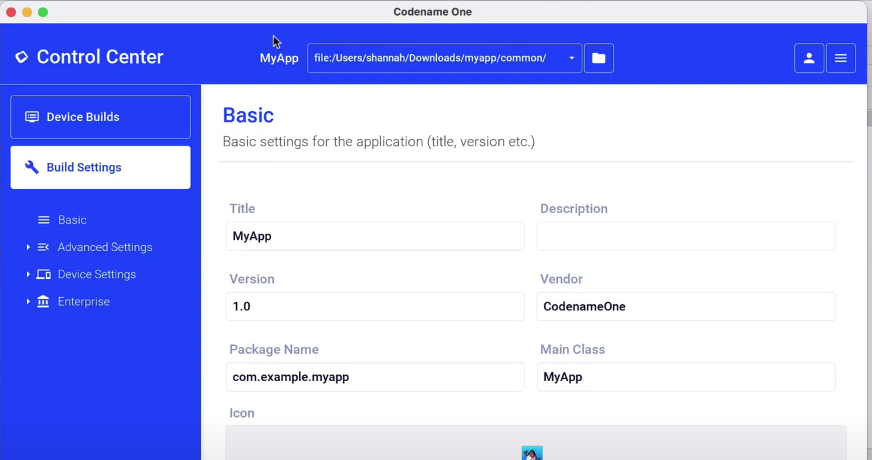
To access the certificate wizard, I need to open Codename One Settings. I do this by selecting “Tools” > “Codename One Settings” from IntelliJ’s configuration menu, then pressing the “Run” button.
This will open The Control Center (aka Codename One Settings, aka Codename One Preferences):
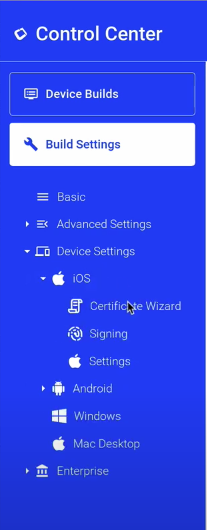
Once there, I select “Device Settings” > “iOS” > “Certificate Wizard” from the navigation menu on the left.
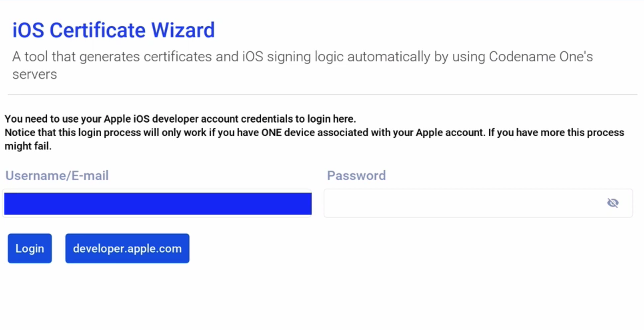
This displays the login form for the certificate wizard:
IMPORTANT: You need to use your Apple Developer account to login to this form. NOT your Codename One account.
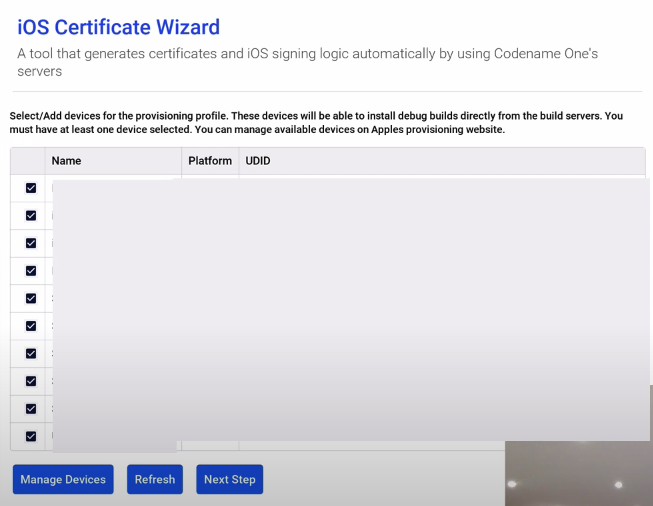
In the video I spliced out some of the waiting time. The login can take a little while, so be patient. Once logged in, it shows me a list of my registered development devices, and I can select which ones I want to be able to deploy this app to for testing and debugging.
The above screenshot has all of the rows greyed out. When you log in, you’ll see device names and UDIDs listed on this form.
Generally I select all of them. If this is your first time building an iOS app, then you may not have any devices listed yet, and you’ll need to click on the “Manage Devices” button and follow the instructions there.
Next, it asks me to confirm that I want to regenerate my certificates, as it has detected that I already have certificates generated in my Apple account. In my case, I say “yes”, I’d like to regenerate them, but in most cases, you would select “no”, to just use your existing certificates.
TIP: If your certificates were generated by the certificate wizard, then a copy of them has been stored inside the $HOME/.codenameone/iosCerts directory, and the wizard will use them automatically. If they weren’t generated by the certificate wizard, and you choose not to regenerate them, then you may need to specify the location of your certificates in the iOS Settings section.
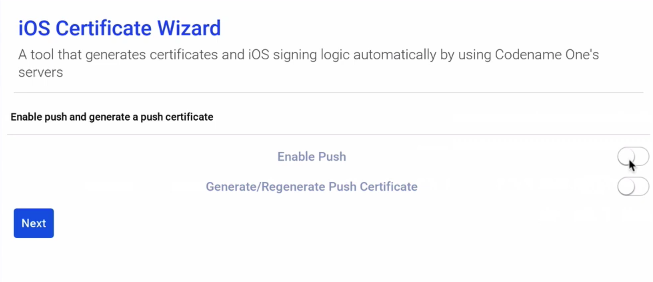
Next, it asks whether we want to generate push certificates. In this case, since this is just a basic Hello World app, we don’t need push, so I leave these options OFF.
After clicking next, it will churn for a bit, and if all goes well, it will show us the message that our certificates were generated and installed successfully.
Just to be sure that my settings are saved. I click on the hamburger menu in the upper right, and select “Save”.
Sending the Build
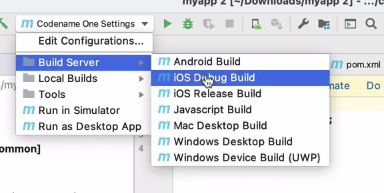
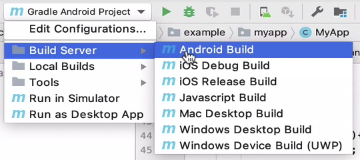
Now that the certificates are generated, we can send the build. Back in IntelliJ, I select “Build Server” > “iOS Debug Build”
NOTE: If this is your first time building with the build server, you may be prompted for your Codename One username and password.
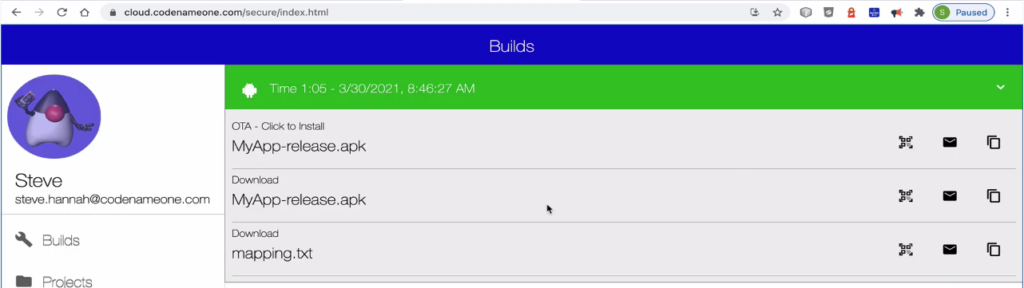
I then follow the progress of the build on the Codename One website.
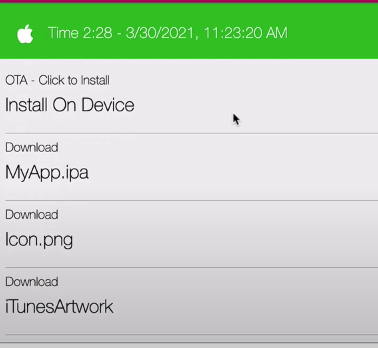
When it’s finished, I get a set of links to do things like download the .ipa, or install the app on device.
Get Started
Getting started with your own native app is really easy. Just go to the Codename One initializr, enter your app details, and press “Download”.
The other day I stumbled across this post whose title seemed to suggest that Flutter is not a cross-platform framework.
The thrust of his article is that, even though Flutter allows you to build your app for 6 platforms, that doesn’t mean that you should:
Yes, you can deploy your app on 6 platforms, but honestly, I am not planning to do so. Basically, because YOU SHOULD use different design patterns depending on the platform. I can’t imagine deploying my apps on a different platform.
At first glance, he appears to be arguing for writing separate apps for each platform (e.g. Android, iOS, Mac, Windows, etc…). This idea that you need to write a separate app for each platform using the platform’s native UI toolkit is widespread in the developer community. “Native Widget Maximalists”, as I call them, believe that using cross-platform UI libraries will result in a sub-par, “non-native” experience, and will, therefore, be rejected by the user. Generally, adherents to this philosophy are fine with sharing “business logic”, but the user interface must use the native UI widgets. Much of this dogma is based on dated observations of clunky, cross-platform, desktop apps of the mid to late nineties – many of them developed by novices using early incarnations of Swing.
Since that time, cross-platform toolkits have matured, and platforms have converged on some common UI design patterns. This is especially the case on mobile, where many popular native apps look nearly identical on Android and iOS. Mobile developers have realized that it is more important to create a nice, consistent design than it is to try to “look native”. Yes, there are differences between iOS and Android, but the differences are the exception – not the rule. In my opinion it is overkill to maintain two separate codebases for the 2% of the UI where they diverge. Better to provide abstractions that allow that 2% delta to be satisfied in platform-specific ways.
If you read further into the article, you’ll see that the author actually isn’t a “native widget maximalist”. I.e. He isn’t arguing that you should build separate apps for iOS and Android using their native SDKs. He isn’t even arguing that you need to write separate apps for iOS and Android.
Usually what works on mobile won’t work on desktop and the other way around.
What he’s saying is that you shouldn’t deploy the same app on desktop as you do on mobile, because the form factor is too different. If this is his thesis, then I agree with him… with some caveats.
Strategies for targeting multiple form factors
Disclaimer: I work for Codename One.
Two of the best cross-platform development tools for mobile development are Codename One and Flutter. They approach the problem of cross-platform development in very similar ways. Both provide 100% code reuse across platforms. Both provide a rich set of UI components and API abstractions for the underlying device capabilities, and both can be deployed to iOS and Android (and other platforms), as native apps. Codename One apps are developed in Java and/or Kotlin. Flutter, in Dart.
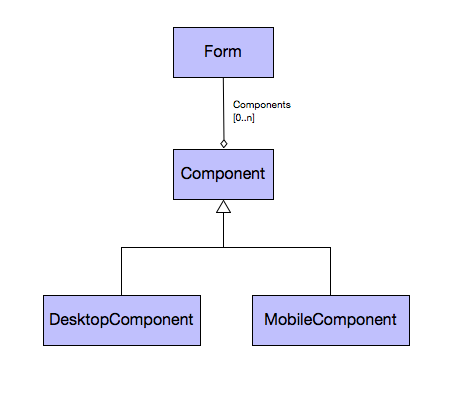
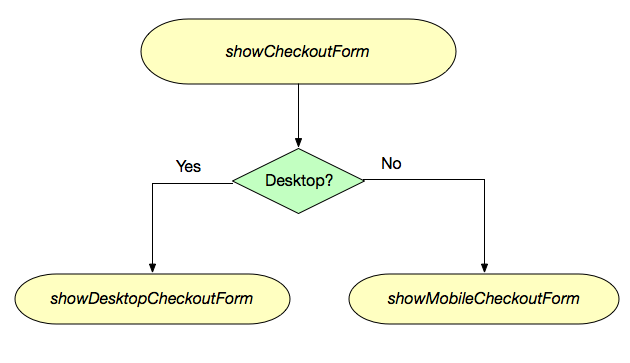
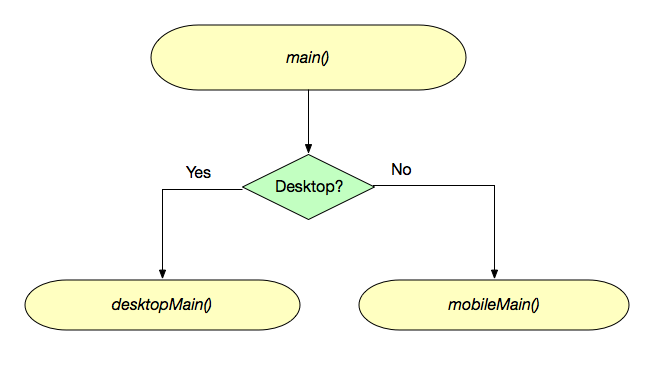
Both Codename One and Flutter also allow you to deploy your app as a desktop app. However, if you don’t tweak your UI for the larger screen-size, and desktop usage patterns, the result probably won’t be very good. Even using mobile apps on tablet feels forced if you haven’t customized the UI for the larger screen-size. There are four strategies I use when building a multi-form-factor app (i.e. an app that runs on mobile and desktop):
1. Responsive UI
This is where the app logic is essentially the same across both form-factors, but the layout manager, and styles are “form-factor”-aware. E.g. On tablet/desktop they use different styles, and the layout managers position elements differently. (E.g. Instead of a hamburger button that reveals a side-menu sliding out over top of the form, the side menu is always visible).
2. Component-level abstraction
This is where most of the app’s control flow is the same, but certain parts of each form are abstracted to allow for different implementations on desktop, tablet and mobile. This may involve using a different widget for editing some field, displaying some extra sections on desktop that aren’t visible on mobile. This is very similar to Responsive UI, and there is certainly overlap. The distinction is that with Responsive UI, you are keeping all of the same UI elements – you’re just rendering them differently. With component-level abstraction, the UI form may actually include different UI components with different logic on desktop than it does on mobile.
3. Alternate views
This is where the app’s control flow is the same, but you create entirely different views on mobile than on tablet. If you are very careful with the design of your views, you may be able to reuse your controller classes, as long as the views share common APIs, and fire compatible events. Keeping them in sync can be challenging, so quite often you would also write separate controllers as well.
4. Separate control-flow
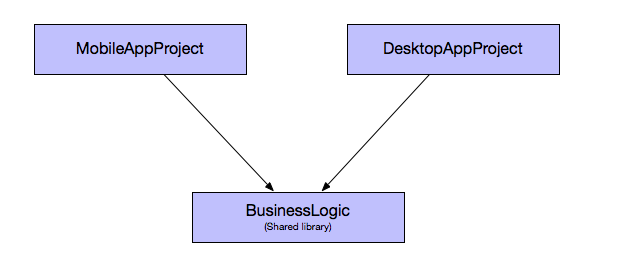
This is where you are basically implementing two separate apps. You can reuse business logic, but the UI layer is written separately for tablet/desktop and mobile.
5. Separate apps
If you are already implementing your app with separate control flow, then creating separate apps is just one small additional step. Generally you would still share all of your business logic between the apps. You would just provide alternate entry points for the different apps. With Codename One, this can be achieved either by moving all of the code into a shared library (cn1lib), or by simply providing an alternate configuration file (codenameone_settings.properties) that specifies a different main class. Most build targets use Proguard, or equivalent, to strip out unused code, so the app size isn’t impacted by the code-sharing.
Best choice?
It appears that the author of the article is arguing for option #5 – Separate apps. His preference, he says, is informed by his experience working on large enterprise systems where there would be different teams working on the apps for different platforms, and keeping it all in the same app would lead to toes being stepped on. Option #4 (Separate flow control) should adequately address his concern as well, since each form-factor would have its own package, likely, and developers wouldn’t need to tread on anyone else’s garden.
My preference is to use the lowest number on that scale that I can get away with, and progress up the ladder as required. IntelliJ makes refactoring from one strategy to another mostly painless, and the less fragmentation there is in the code-base, the easier it will be to maintain – generally. Obviously adding team members, or splitting the project into multiple teams changes that maintenance calculation.
Still prefer a cross-platform development tool
Suppose your team decides to implement separate apps for each form-factor (Mobile, Tablet, and Desktop). Let’s even go a step further and suppose that you decide to implement separate apps for each platform (Android Mobile, Android Tablet, iPhone, iPad, Mac, Windows, Linux). Then is there still any benefit using a cross-platform toolkit like Codename One or Flutter? Since you’re doing separate apps, wouldn’t it be just as well to just use the native APIs?
Unless you have an unlimited supply of time, developers, and money, then the answer is “no”. You would be much worse off by choosing to use separate native SDKs for each platform. Even if you manage to write some shared modules that you were able to share between the projects, the complexity involved in maintaining separate codebases is staggering. Everything is 7x more difficult. Every bug is fixed 7 times, and testing gets ridiculously complex. In addition, keeping up with the latest on all of these platforms and APIs takes dedication. You would likely need to bring in separate teams for each platform – and very little of the work can be shared between the teams.
Using a technology like Flutter – even if you are building 7 separate apps, would be far easier. Sharing code between projects is much easier, and every developer can work on every project without facing barriers to entry imposed by the idiosyncrasies of each native API.
Summary
Just because you can deploy your app to 8 different platforms, doesn’t mean that you should. Deploying to multiple platforms within the same form factor (e.g. phones) is a solid approach with a proven track record – with countless popular apps on the iOS and Android app stores currently developed with cross-platform tools like Codename One and Flutter. However, deploying to multiple form-factors (e.g. phone and desktop) is more difficult, as what works on one form-factor, may not work well on another. You may be better served by creating separate projects for each form factor, and sharing business logic between them. This doesn’t mean that you should drop your cross-platform development tool (e.g. Flutter/Codename One). Using such a tool is still a benefit as it reduces the combined project complexity, and makes it easier to share code and developers between the projects.
In this video I demonstrate how to build an Android app with this project.
TLDW (Too Long Didn’t Watch):
Here’s the gist of the video. There are two different build options for Android:
Build Server > Android
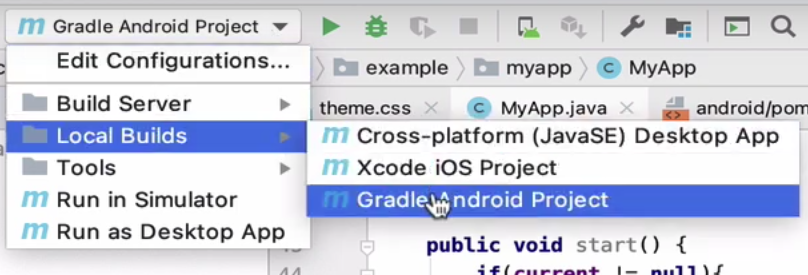
Local Builds > Android Gradle Project
In this video, I start with option 2, “Android Gradle Project”. This option does NOT require a Codename One account, and performs all of the build on your local machine. It does require that you have Android Studio installed.
I select “Local Builds” > “Android Gradle Project” from the Configuration menu of IntelliJ, and then press “Run”.
This generates an Android Studio project, and automatically opens it in Android studio.
I then press “Run” in the Android Studio, and wait while it builds and installs the app on my Android Emulator.
In the second part of this video, I use the “Build Server” > “Android” build option, which is much simpler, and doesn’t require you to install Android Studio. All you need is IntelliJ (Actually you don’t even need IntelliJ, as you could just build the project using Maven), and it will use the Codename One build server to generate the Android app.
After selecting “Build Server” > “Android” from the configuration menu, I press “Run” to start the build.
It then redirects me to the Codename One dashboard where I can monitor the build progress and, download the app when it’s done.
More Background
When we decided to migrate to Maven, we also made the choice to add official local build targets so that developers are no longer reliant on the build server to build their Android and iOS apps. Building locally has always been an option, but it was difficult, and we didn’t provide support for it. By adding an official local build option, we are hoping that developers who balked at Codename One because they didn’t want to be reliant on us for their builds will give us another look.
If you haven’t heard of Codename One yet, I encourage you to check us out. In my biased opinion, we are the best game in town, if you’re looking to build native mobile apps in Java or Kotlin.
It only takes a minute to create and build your first project using Codename One initializr.
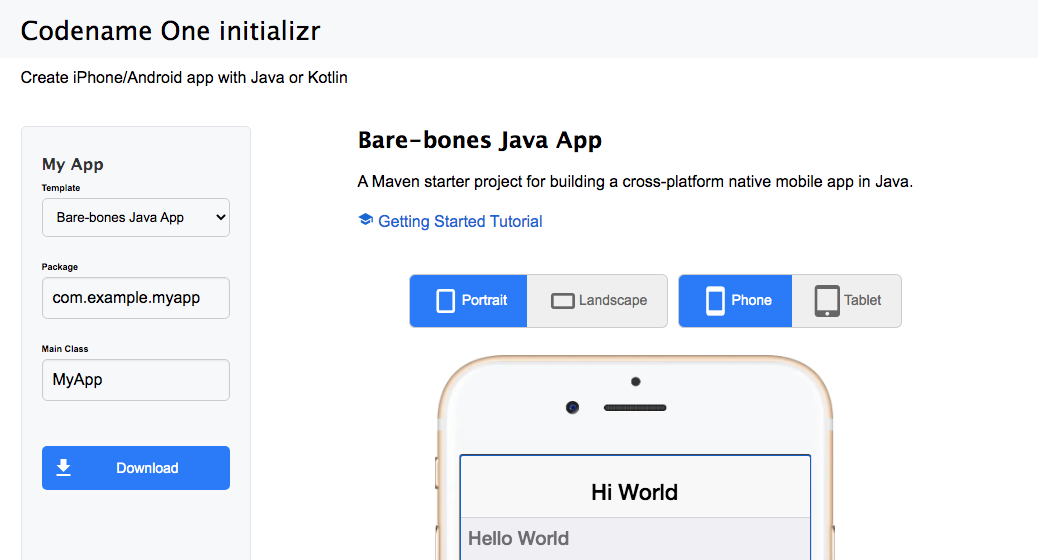
The Codename One initializr is an online tool for generating a Codename One starter project. You can select either Kotlin or Java, then you can download the project and open it in your local IDE.
In this 5-minute video I use the initializr to generate a bare-bones Java project, which I open and run in IntelliJ. I also give a brief tour of the project structure and build targets.
TLDW (Too Long Didn’t Watch):
Here’s the gist. Go to Codename One initializr, select either the “Java Bare-bones Project” or “Kotlin Bare-bones Project” from the “Template” select box, and press “Download”
Extract the resulting project, and open it in IntelliJ (or your preferred IDE).
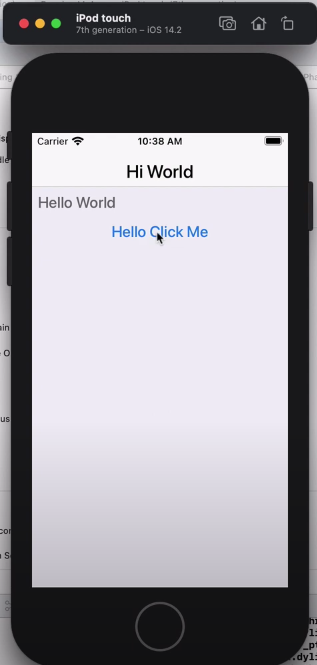
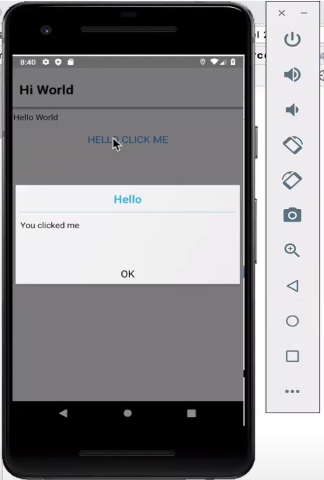
Press “Run” and wait while Maven downloads the build dependencies. It will open the Codename One simulator with the simple “Hello World” app running.
The project is a Maven project, with the following build targets:
iOS
Android
Mac Desktop
Windows Desktop
Javascript App
Windows UWP App,
JavaSE Desktop App
Xcode Project
Android Studio Project
In the video, I also demonstrate how to add a Button that, when clicked, opens a dialog. This is achieved by opening the common/src/main/java/com/example/myapp/MyApp.java file, and adding the following to the start() method:
I’ll soon be posting some follow-up videos to demonstrate how to build and deploy the project to iOS and Android devices, so watch the RSS feed or follow me (wherever you receive my posts), to be notified when these are posted.
More Background
I’ve been working hard over the past several months to migrate Codename One from Ant to Maven. That process is now complete, and it has enabled us to introduce a new, simpler workflow for creating Codename One projects. The Codename One initializr uses our Codename One App Project maven archetype to generate a starter project. Right now we just have two starter templates: Bare-bones projects for Java or Kotlin. We will be adding more templates soon, including some templates for full-featured apps that you can take and customize.
I’ve very proud of this work, and I’m excited about some of the new things that it will enable.
If you’re a Java or Kotlin developer and you’re interested in making cross-platform native mobile apps, you should give Codename One a try. You just might be surprised at how pleasant the experience is.
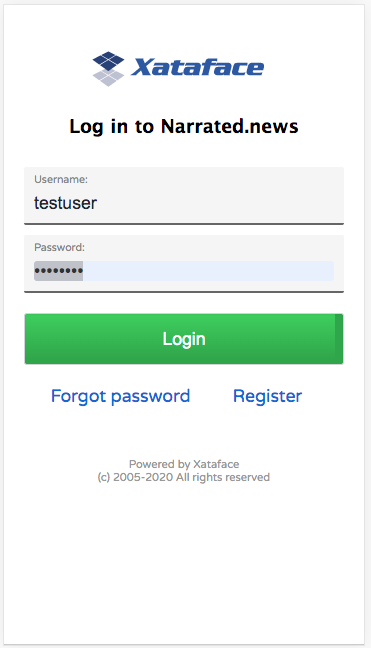
During my two week “vacation” from Codename One, I’ve been madly working on a new project using Xataface. For this project, I really needed the mobile interface to be smooth, so I decided to finally make Xataface’s core theme responsive. Along the way, I also made numerous improvements to the flow of the UI especially in relation to sorting and filtering results. Before I go into detail about the new features, here are some screenshots of my app, which uses this new mobile theme.
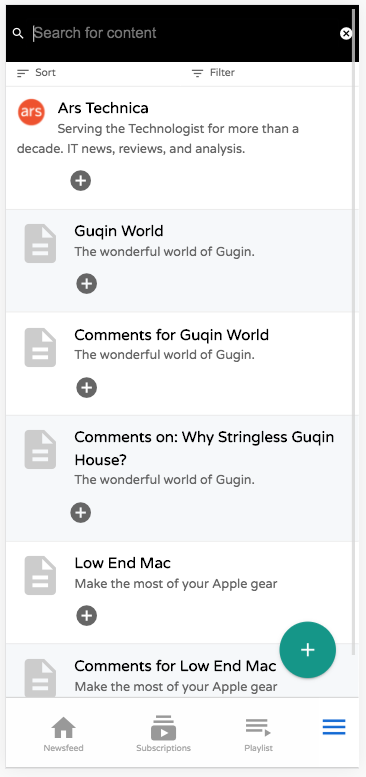
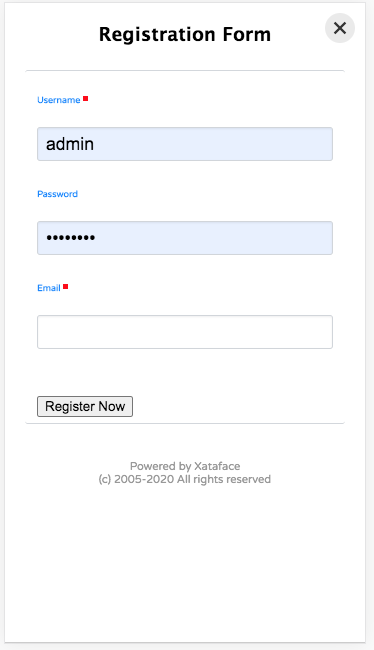
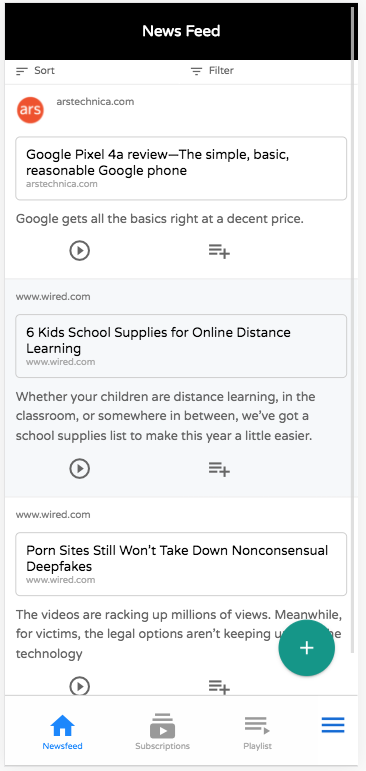
The new login screen is much cleaner and mobile friendly.The mobile registration form – fields generated based on the fields in the users table.The list view for the “News Feed” table.
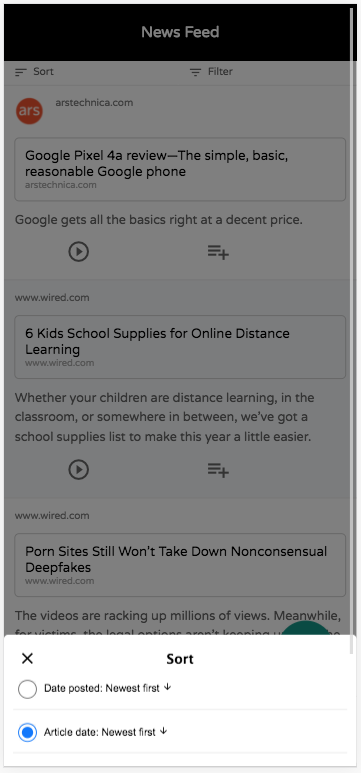
Let me unpack that above screenshot of the list view to highlight the various aspects you can see here.
The “tables” menu is rendered along the bottom of the screen as tabs.
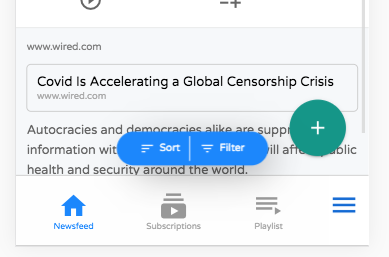
Sorting and filtering buttons are rendered at the top of the list. When you scroll down the page, these buttons are converted into floating buttons:
Notice the Floating Action Button in the lower right for adding new records. . By default this shows the “New” and “Delete” actions, but you can add your own actions to this menu using the “table_actions_menu” category.
Notice that action icons below each row. These are rendered from the “list_row_actions” category.
Sorting
Clicking on the “Sort” button displays a sheet with the various options available for sorting.. You can select which columns should be sortable in the fields.ini file using the new sortable directive.
Filtering
Clicking on the “Filter” button displays a sheet with the various options available for filtering.
This filter dialog is “live”. The button at the bottom that says “Show 977 Results” will dynamically update as you enter your query so that you can see how many results there will be.
Optional Search Header
On some tables you may want the header to be a “search” field. This can be achieved using the the new fieilds.inii “search_field_header” directive, as demonstrated in this table:
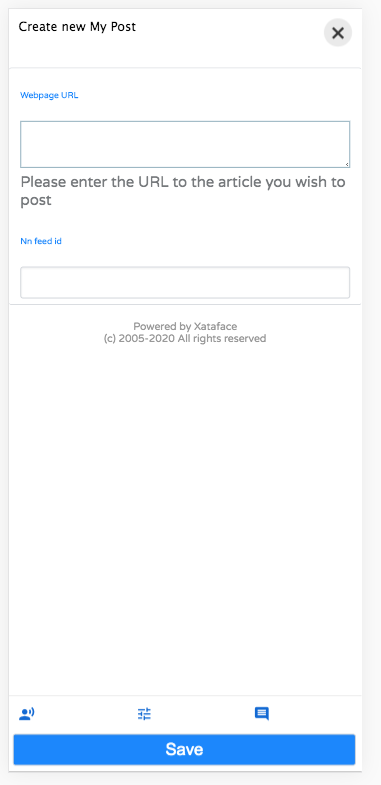
New/Edit Record Forms
Forms are Xataface’s bread and butter, so they need to be very mobile friendly. I’ve completely revamped the stylesheet to be responsive so that forms are a pleasure to use on the smaller displays.
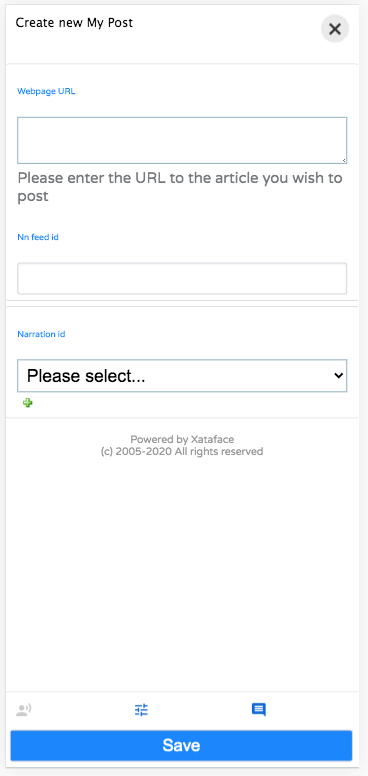
I’ve also added a new feature to help reduce clutter on forms. You can now make field groups “hidden” by default. Hidden field groups are collapsed into buttons that are rendered at the bottom of the form:
The user can display a hidden field group by clicking on the corresponding icon. E.g. In the example form shown above, the user might want to edit the “narration”. They can do so by clicking on the “Narration” icon at the bottom of the form, which will reveal the narration-related fields.
More to Come
This is just a quick post to share some of the work. There are tons of new features that I didn’t cover here. I’ll be blogging more about them soon.
I’ve been slowly assembling a “definitive” guide for Xataface. You can see the current version (in progress) at https://shannah.github.io/xataface-manual/
After I’ve ported all of the existing documentation into this manual, I’ll be using it as the basis for a new website. There is lots of new stuff in the pipe for Xataface, so stay tuned.
Ramblings about Xataface, Java, and other software development issues












 . By default this shows the “New” and “Delete” actions, but you can add your own actions to this menu using the “table_actions_menu” category.
. By default this shows the “New” and “Delete” actions, but you can add your own actions to this menu using the “table_actions_menu” category.
 . You can select which columns should be sortable in the fields.ini file using the new
. You can select which columns should be sortable in the fields.ini file using the new