Normally I use my blog to write about software development, but I’ve decided to branch out a bit with this entry. In order to help my fading memory, I’ve decided to try write about small episodes that I can still remember from my life so that I can “record” them for later.
The ones that are suitable for public consumption, I may post on my blog.
So the first instalment of this follows:
The Fight
Everyone loves a good fight. Or at least all men enjoy a good fight. Or, at the very least, all boys love a good fight. So when word spreads that two boys are going to get into a fight at lunch time in grade 7, everyone marks it on the calendar.
I don’t recall the reason for the fight, but it didn’t really matter. All that mattered was that Trevor and Kris were going to have a fight at lunch time. Real fights were a very rare and precious thing. Of course, we were all experienced “play†fighters, but that was different than a real fight. The fact that we had never had a “real†fight at school didn’t didn’t feel like a fact at all. Television had provided us with vicarious memories of countless “real†fights, so I felt like I was a veteran at this fight-watching game.
At 5 foot 10, Kris was the tallest boy in my grade, but not particularly stocky. Trevor was more typical in height. Frankly I don’t remember what a typical height was for a boy in grade 7. I know Kris’ height because he was the tallest. I was 4’11â€, which I remember because I was, well, me. And because I was one of the shortest boys in my grade consistently up to that point. I even had the honor of holding the class placard during class photos a few times. So when I say that Trevor was a typical height for a boy that age, I would guess he must have been between 5’2†and 5’6â€.
Given the height difference, the smart money was on Kris winning the fight. There was no talk about what the rules were. At least that I can remember. Fight rules were considered self-evident to a 12 year old boy. We imagined that the fight would be over when one of the boys was knocked down or started crying, or “tapped†out. Having grown up with a steady diet of Rocky, I didn’t imagine a “knock-out†was a real possibility. Despite my Dad’s insistence that no human being could withstand the kind of punches that Rocky took by the dozen – I preferred to believe the humans could take 15 rounds of heavy-weight level punches to the face and walk away with only a few bruises.
The morning of the fight, every boy in Ms. Rempel’s grade 7 class was looking up at the clock more frequently than usual. We were counting down the seconds to the 12 o’clock lunch bell so that we could attend the highly anticipated “fightâ€. Finally, the bell rang so we could get our lunches from the cloak room. Only 15 more minutes… we had to eat our lunches inside the classroom. The 12:15 bell signaled that it was time to go outside to fight… er.. play.
As I mentioned before, this was the first scheduled fight that had ever happened at Peterson Road, so there was no protocol in place. No agreed upon time or place. Only an agreement that it would happen. The first 10 minutes of lunch were spent wandering around the field with everyone asking each other if they knew when or where it was happening. Pairs of us roamed the field, then merged with other pairs and continued roaming as a group until most of the grade 7 (male) student body was roaming the field together. We settled on a venue near the back of the field. Somewhere sufficiently remote that the school supervisors wouldn’t notice what was going down. At some point the group fanned out into a circle to give the combatants a makeshift ring inside which they could safely “fightâ€. For a good long while, though, Trevor and Kris just stood there at the perimeter of the ring, both acting shy, as if this were an elementary school dance where the boys and girls just stood on opposite sides of the gym – too shy to ask anyone on the other side to dance. At least that’s what our elementary school dances looked like, but I digress..
At some point someone, probably John, said “so is there gonna be a fight or what?â€. John was always good at frank ice-breakers. Trevor slowly approached his taller opponent and wound up with a punch
Truth be told, this happened nearly 30 years ago, so I can’t provide an accurate blow by blow. I do remember that each boy landed at least one punch, and the consensus was that Trevor had fared much better than we expected – and in fact may have even won the fight. It was not a stellar display of martial arts skills. It resembled a hockey fight, where both players spend most of the fight all tied up in their own jerseys. Neither fighter had any ground game, which would have come in handy once it morphed into a wrestling match with Trevor and Kris rolling around on the grass.
Unfortunately, our fighting circle was not as inconspicuous as we had hoped. It only took a minute or two for the noon hour supervisors to descend on us and stop it. Trevor and Kris were pried apart. No big bruises. No blood. Both had red faces partly from the exertion, and partly from having taken a blow or two to the face.
After Kris and Trevor were led on a perp walk to the office, some of the rest of us were summoned to principal Swoboda’s office as well.
Now, in my recollection, there were between 5 and 10 of us in the principal’s office, waiting for him. In retrospect, that number doesn’t jive with my earlier image that the “entire male grade 7 student body†was attending the fight, as there were about 30 boys in my grade. I can think of a few explanations for this discrepancy, but in any case, there were 5 or 10 of us in the principal’s office. I remember specifically Steve (the other Steve), John, Ezra ,and Quinn, but there were others.
Mr. Swoboda, always a busy guy, burst through the door and sat down at his desk.
“Do you know why you’re here?â€, he asked, rhetorically.
We all looked around at each other – knowing that it wasn’t wise to volunteer to become the spokesperson for this group. “You’re here because, if not for you, this fight would never have happened. The people who watch a fight are just as much, or more, of a problem than the fighters themselves.â€
He then began to address each of us individually. Asking questions like “do you think it’s smart to be encouraging your friends to fight†etc…
When he came to me, he asked. “And you! I’m surprised to see you here. What do you have to say for yourself?â€
My response: “I guess I fell into peer pressureâ€.
 . By default this shows the “New” and “Delete” actions, but you can add your own actions to this menu using the “table_actions_menu” category.
. By default this shows the “New” and “Delete” actions, but you can add your own actions to this menu using the “table_actions_menu” category.
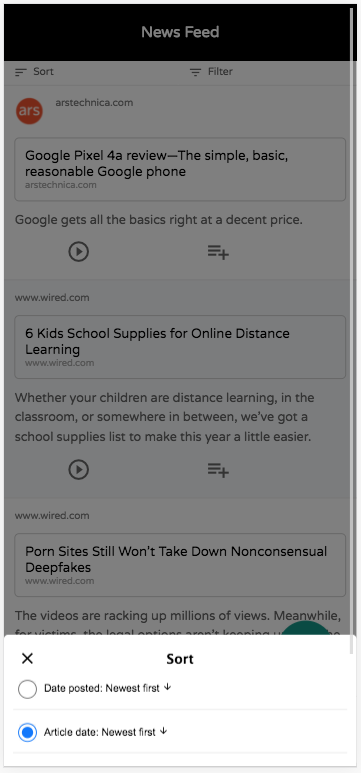 . You can select which columns should be sortable in the fields.ini file using the new
. You can select which columns should be sortable in the fields.ini file using the new 


{kind=link}