
SOFTWARE DEVELOPMENT, STORIES, THINGS I LIKE
Do Kids Still Read Computer Books?
I still remember my first computer programming book. It was a glossy, black, brick of a book on PERL 5. I had started building web pages a few months prior, using the copy of Adobe PageMill that came with my bondi-blue iMac. It didn’t take long before I outgrew the “what you see is sort of what you get” interface of PageMill and started coding the HTML by hand. And it wasn’t long after that, that I entered the world of “copy-and-pasting Javascript” to gain a level of interactivity in my pages – or at least some scrolling status bar text. I started with a free Tripod account, but soon upgraded to “paid” so I could be rid of that pesky banner ad in the header.
In those early days, I learned mostly by viewing the page source of other webpages, and tried to make sense of the HTML code. One of my first projects was a “Search Remote” – basically a popup search window where people could select from a list of popular (and unpopular) search engines, and enter a query. We provided links that Netscape and Internet Explorer users could drag up to their bookmarks bar to make it easy to open the remote. At the time, there were a few search engines, notably GoTo.com, that would pay you a penny or two for each search query, so I would place these engines first in the list, and wait to get rich. I didn’t get rich, but I did learn a lot about HTML, Javascript, and search engines, and I pushed up against their limitations pretty quickly.
Below is a screenshot of the search remote installation page that I pulled from a Wayback machine capture from 2001. It’s missing some images, but you can get the idea.
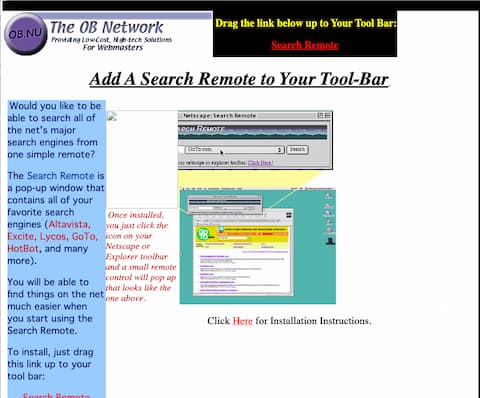 Screenshot pulled from the Wayback machine showing the install page for the Search Remote. Capture was from 1999. It’s missing a few of the images.
Screenshot pulled from the Wayback machine showing the install page for the Search Remote. Capture was from 1999. It’s missing a few of the images.
Back then, all of the search engines were pretty bad, so it was common practice to do a sort of “pub crawl” through all the main ones until you found what you were looking for. You’d start with Altavista (the search engine with the largest index), then you’d try Excite and Yahoo. If you still didn’t find what you were looking for you might try Lycos, Infoseek, or even AskJeeves. This is where my Search Remote comes in. Rather than have to navigate to 6 different search engines’ websites, you could perform all the searches from one place. It worked pretty well, but It still required the user to perform separate queries for each search engine. I wondered if there was a way to let the user perform a single query and have all of the results from the different engines combined into a single result set.
Meta-Search Engines
Sometimes, when you’re stuck on a problem, the watershed moment is simply learning the correct terminology for what you want to accomplish. In my case, as I soon learned, the name for what I wanted to build was a “meta search engine”, and I was not the first person to conceive of such a thing. Meta-search engines would allow a user to submit a single search query to a server-side CGI script, which would relay the query to 5 or 6 major search engines, in the background, and return all of the results back to the user. Some of them would merge the results into a single set, and sort them according to its own relevancy algorithm. Others would keep the results separate, presenting them on a webpage organized by search engine. Dogpile, my favourite meta-search engine at the time, would use the first method: merge the results into a single list, so it felt like a first-class search. (Side note: Just did a search and it looks like Dogpile still exists).
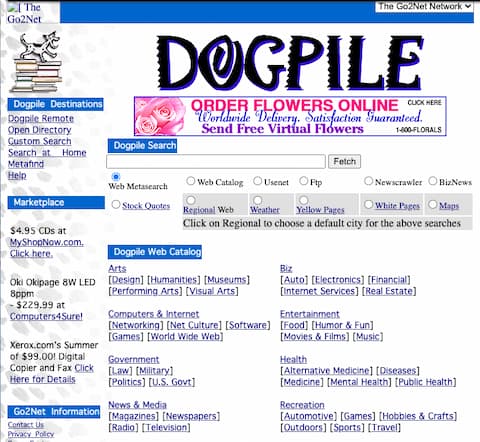 Dogpile meta search as it appears in the wayback machine from Sept. 2, 1999)
Dogpile meta search as it appears in the wayback machine from Sept. 2, 1999)
See Dogpile on Wayback Machine
Without a server-side script, it is really hard to write a meta-search engine. This was before AJAX, so the only way to load things from the server from Javascript was using submission forms, and frames. We didn’t even have iframes yet. I tried to build one using pure Javascript, but the results left something to be desired. The best I could do was create a window with a separate frame for each search engine. This worked okay when there were only two search engines, but anything more than that and your “productivity” gains get lost in the clutter of tiny frames.
CGI: The Undiscovered Country
I think that most programmers have a certain resistance to learning new technologies, I was no different. I had cultivated familiarity with Javascript and HTML, but server-side programming was a remote country whose border crossings might as well have been guarded by barbed wire and machine guns. Not until I had exhausted all avenues on the Javascript side of that border, did I decide to venture forth into the untamed world of PERL. I started with things that were freely available online, such as the CGI specification, and the odd PERL tutorial. But the online ecosystem for programming tutorials was sparse, and discoverability was poor – nothing like today, where you can type in just about any programming topic you want, and find tutorials, examples, videos, tutorials, open source projects, and memes enough to keep you busy for months.
One day in my travels, I came across a PERL meta-search script that someone had posted on Hotscripts (or some similar free cgi script site). I printed it out with my Epson 740 inkjet printer, and proceeded to study it. At the time, it was a completely foreign language to me. I recall curling up in bed, on the couch, and in the hot-tub for hours at a time with these pages, poring over it line by line, trying to understand what was going on. It was like one of those pictures they used to display in shopping malls, where, at first, it looks like just a mess of textures, but if you stare at it long enough, you start to see a 3-D image emerge. This script, which, at first, was just a sequence of gibberish, would start to reveal its structure to me in fleeting moments of clarity.
The hours I spent studying that script were important to my growth as a programmer. I still didn’t fully understand what everything meant, and I certainly couldn’t have written my own search script yet, but it did provide me with a feel for what PERL looked like and, strangely, what it felt like. I was ready to graduate to the next level: an actual computer programming book.
Did I mention that I was broke at the time. I had started making webpages just at the end of a six month failed entrepreneurial adventure with a friend, and I was down to about twenty dollars in my bank account on a good day. Luckily, I was living at Casa de my parents where rent was reasonable (free), but I didn’t have a lot of money to spend on frivolities. Or essentials. That was OK, because I was going to be getting rich from my search remote any day now.
To the Bookstore
So, when I entered my local Chapters to shop for computer books, I might as well have been shopping for high priced commercial real estate, as both were out of my price range. Computer books went for anywhere from $60 to $120 depending on how “hot” or specialized the topic was. Lack of funds did not deter this dreamer, though. I scanned through the tables of contents of several dozen books, trying to identify the one that spoke most directly to my interests. When I was a child I used to spend hours examining the toys section of the Sears Christmas catalog, imagining what it would be like to have all of these cool toys and sets. This was that, except replace “Masters of the Universe” with “Mastering PERL”.
After what seemed like minutes, but was probably closer to an hour, I had settled on this PERL book. It promised me close to a thousand pages of secrets that, up until now, the universe had greedily kept from me. All I had to do was figure out how to pay for it. A rich benefactor, perhaps? That rich benefactor ended up being my Dad. I made a deal with him to build a website for his band if he bought the book for me. It was a win win. This book was my first real glimpse into the world of programming. Every page opened my eyes to new possibilities. Things I could build. With every new concept, my mind would start wandering to computer programs I had used in the past, and wondering if I could build something like them – or better.
I could fill a school gymnasium with the spaghetti code that this book (and the hundreds that followed it) inspired. When I later got a job, I started buying a new computer book every payday. Sometimes three or four books. Books on Java, PERL, PHP, HTML, Flash, Servlets, Applets, Game development… you name it. I was hooked. When computer books became more affordable and discount stores like “Half-priced Computer Books” started popping up, I was no longer only buying books on topics that interested me. I began buyings books that I might someday be interested in. I thought I’d won the lottery when, one day, I found a bookstore that was going out of business, and the owner said I could fill 4 big boxes with books for only $100.
Side note : See my post about that time I wanted Star Wars on LaserDisc but ended up with more than I had bargained for. Same personality traits seemed to dominate there as did here.
We are now almost twenty years removed from the computer books hay day. Book stores stock a paltry few books on programming now, and buying books on Amazon isn’t the same. I like to be able to pick up a book, thumb through it, and, um, smell it before I buy it. It’s not a purchase – it’s an experience. I still frequent the computer books section of Value Village to see if I find anything interesting. Some recent hauls included The Macintosh Bible (7th Edition, 1998), Core Web3D (1999), and Core Swing Advanced Programming (2000). I love reading the preface and introduction sections. They add history and context to these old technologies, and serve as a sort of time capsule that reveals how the world looked to software developers at that time. I love reading 20+ year old predictions about the future, and laughing about how wrong they were, or marvelling at how spot-on they were.
 A few of the retro computer books that I picked up recently from Value Village
A few of the retro computer books that I picked up recently from Value Village
Old man yells at cloud, reflects on good ol’ days
I wonder, if I were just getting started now, would I still gravitate towards the thousand-page textbook as a preferred method of learning? Or would I just watch a Youtube video. Information is so much more accessible than it was in the nineteen hundreds and there are many new forms of media that are available. There are online communities, question/answer sites, online courses, and video tutorials for just about everything imaginable on Youtube. For free! I suspect that “kids” these days don’t even bother with books. If that’s the case, then oh what a shame. They are missing out on a rich, comprehensive, noise-free medium that gives pure escape from the real world.
I’m not sure how many computer books I currently own. Probably more than 200 and less than a thousand. Most of them are stored away in boxes, spread between my parents’ basement, my garage, my furnace room, and my office, but few coveted titles still enjoy the prestige of sitting on my bookshelf.
My latest project
The Search Remote didn’t exactly strike gold, but I have high hopes for my most recent project, Tuxpin, which builds on my love for audiobooks and podcasts. It is an app (available on both iOS and Android) that allows you to listen to webpages in your podcast app. That project was built using many of the same technologies that I learned how to use at the beginning of my programming journey. PHP, MySQL, and Java. Sadly, it doesn’t contain a single line of PERL.
 ]5 The website for my latest project, Tuxpin, which allows you to listen to webpages in your podcast app.
]5 The website for my latest project, Tuxpin, which allows you to listen to webpages in your podcast app.
Footnote:
I might have the original files for the search remote still stashed away on some 4 gigabyte hard drive, but it would require a lot of effort to retrieve it. But, in the same spirit that supplanted reference books with Google+Stack Overflow, I decided to do a quick search on the Wayback machine to see if it had any record of my debut web project. To my delight, they had both my “Homepage” project, and the search remote project. They are missing most of the images, but the page structure is there, and the search engine select lists are intact so you can see which search engines we supported. I’m impressed at the comprehensive list that I amassed. I must have had a lot of time on my hands.
Photo by Sharon McCutcheon on Unsplash