I am always experimenting with new technologies just to see what new cool things are possible. As a Java developer, I’m usually toying with JVM-related technologies. The latest new and cool technology that I have been experimenting with is TeaVM: A JVM for the browser. After using it for about 2 months now, I am confident in saying that TeaVM is awesome!
TeaVM vs GWT
Java in the browser is nothing new. GWT has offered Java to Javascript cross-compilation for years. So how is TeaVM any different or better than GWT?
- TeaVM operates on Java byte code rather than source code. This means you can convert precompiled .class files or even full .jar files to Javascript.
- TeaVM supports (or can potentially support) alternative JVM languages like Scala, JRuby, Kotlin, etc, since it operates on .class files (which all JVM languages ultimately compile to). GWT is limited to just Java.
- Multithreading. This is groundbreaking. TeaVM actually supports threading primitives like synchronized, Thread.sleep(), Object.wait/notify, etc.. This is a very new feature of TeaVM. Many have tried to come up with a threading solution in the browser, but TeaVM is the first (in history?) to have successfully done it. See live demo of multithreading
What I’m Using it For
I’m currently working on porting Codename One into Javascript. Codename One is a Write-once-run-anywhere solution for mobile application development. Up until now, it supported deploying apps to iOS, Android, Windows Phone, J2ME, BlackBerry, and the desktop (Windows/Mac)… but notably, it did not support deployment to the web. For the past year, I have been having on and off discussions with the other Codename One developers about the possibility of a Javascript port, but I was advised that it was impossible because Javascript didn’t support multi-threading. Attempts had been made before using GWT but they did not prove successful. Codename One is a heavy user of threading primitives since it maintains its own event-dispatch thread (very similar to Swing), and this would lock up the browser if allowed to run in the Javascript single-threaded environment.
A little over a year ago I came across TeaVM for the first time, and I asked Alexey (its author) whether there was any support for threading. He said “no†at the time, but that he had an idea of how he could implement green threads. At that time I wasn’t working for Codename One and had limited time to spend on projects like this, so I just left it there.
Fast forward to a couple of months ago. I was given the green light to go ahead and attempt a Javascript port. At that time still, it was basically me saying “I think I can do itâ€, but the rest of the team was skeptical, having failed before with GWT. I contacted Alexey again and told him what I was planning to do.
Aside: I was a little naive at this point to think I could do the port with my current knowledge and tools. Knowing what I know now, there is no way I could have succeeded without the the help of Alexey and TeaVM.
At this point I thought I could take the code that was generated by TeaVM and modify it to use Stratifiedjs to support continuations/pseudo threads. He replied that he was aware of this project but that it wasn’t a good fit because he had a better way.
The full thread that shows the development of Async code generation (i.e. multithreaded support) can be see here.
Within days, he had completed a prototype of his new “CPS style†code generator that supported asynchronous code. He implemented Thread.sleep() and Thread.yield() and posted a test case. Based on these implementations, I added initial support for Object.wait(), Object.notify() and a few other threading primitives. Alexey, has since refactored and improved these implementations, such that probably none of my original contributions are recognizable. The full scope and scale of this project, frankly were a little over my head.
I have now been working on the Javascript port for Codename One for a couple of months. There have been quite a few bug reports, but Alexey has been quick to fix them all. I would say that TeaVM’s multithreading implementation is pretty stable at this point. And it is getting more stable daily.
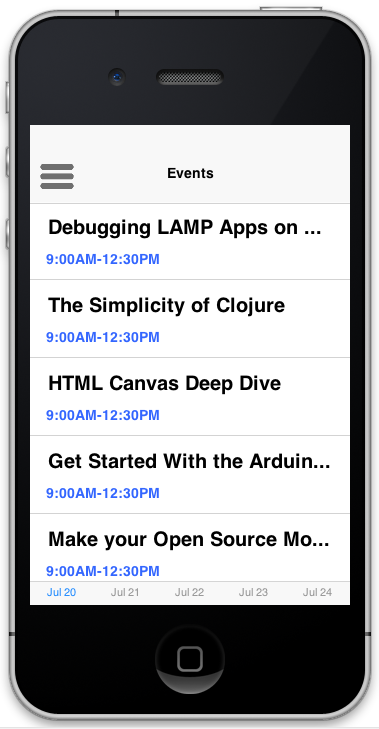
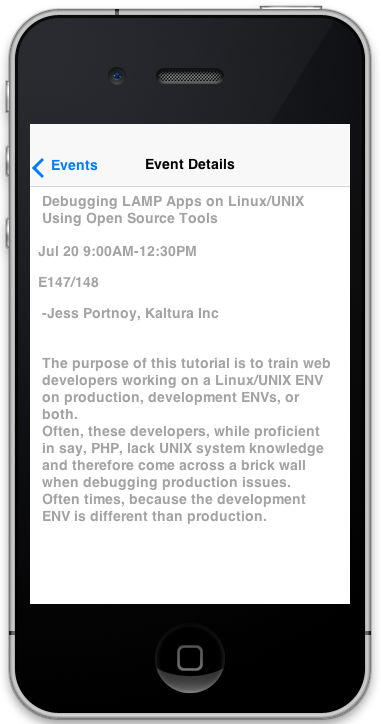
The Poker Demo
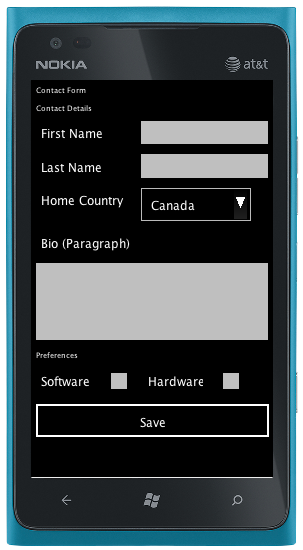
Here is a small teaser of the result of the new Codename One port that is built using TeaVM: the Poker demo. The application itself was not modified from the version deployed to iOS, Android, etc… It just required a port layer to implement the “native” components of the Codename One framework, and the rest was left up to TeaVM to work its magic.
Performance
I have been very impressed by the performance that I have been able to achieve with TeaVM. The generated code is very efficient resulting (give or take) in one line of Javascript code corresponding with one line of Java code.
You might think that adding threading support and blocking synchronous method support would lock up the browser, but you would be dead wrong. TeaVM’s transformation to continuations allows it to provide support for synchronous code without ever blocking the javascript thread. This is because, under the hood, these are implemented using callbacks.
Debugging
Personally I prefer to use Netbeans as my IDE so I’m not benefiting from the debugging support that Alexey created for Eclipse. Therefore, I do my debugging directly in chrome. This actually isn’t as bad as it sounds. Stack traces in chrome are very readable and map directly to the corresponding Java stack trace (i.e. if an error occurs in javascript it is fairly easy to track it back to the original Java code that caused it).
Optimizations
Another nice thing about TeaVM is that it pays attention to things like executable size. It uses static analysis to strip out dead code prior to conversion so that your app is as small as possible. It also includes an option to minify the code, which further reduces the code size.
More to Come
Personally I think that Java needs to be in the browser, since it is essentially the “operating system of the futureâ€. I also think that the browser can benefit greatly from Java as applications get more complex and difficult to maintain. Currently TeaVM provides the best route between Java and the browser, so I expect it to catch on over the following months and years.
Do you currently have a project that depends on GWT? Or do you have a Java project that you would like to offer on the web? You may want to consider porting it to TeaVM because of all of its nice features (i.e. support for other JVM languages, and multithreading). I have had a great time porting Codename One to TeaVM. I’m happy to answer questions or offer tips if you are interested in porting your project over as well. In addition, I think you’ll find that Alexey is very responsive to bug reports, feedback and questions.
For more information about TeaVM, check out its Github repository.